
En un artículo anterior, se comento a cerca de los hilos y multihilos en el sistema operativo, sus ventajas y los tipos de modelos, sin embargo, hoy nos enfocaremos únicamente en lo hilos, para entender la función de este concepto en todo el entorno de la arquitectura de un computador.
¿Qué son los hilos?
El modelo de subproceso es una extensión del modelo de proceso. En el modelo de rosca, cada el proceso puede consistir en múltiples flujos de control independientes que se denominan subprocesos. La palabra hilo se utiliza para indicar que una secuencia continua potencialmente larga de se ejecuta instrucciones. Durante la ejecución de un proceso, los diferentes hilos de este proceso se asignan a los recursos de ejecución mediante un método de programación.
Conceptos básicos de los hilos
Una característica importante de los subprocesos es que los subprocesos de un proceso comparten la dirección (espacio del proceso), es decir, tienen un espacio de direcciones común. Cuando un subproceso almacena un valor en el espacio de direcciones compartidas, otro subproceso del mismo proceso puede acceder a este valor después. Los subprocesos se utilizan normalmente si los recursos de ejecución utilizados tienen acceso a una memoria compartida físicamente, como es el caso de los núcleos de un multinúcleo procesador. En este caso, el intercambio de información es rápido en comparación con la comunicación de socket. La generación de subprocesos suele ser mucho más rápida que la generación de procesos: sin copia del espacio de direcciones es necesario ya que los subprocesos de un proceso comparten la dirección espacio. Por lo tanto, el uso de hilos es a menudo más flexible que el uso de procesos, sin embargo, proporciona las mismas ventajas con respecto a una ejecución paralela. En particular, los diferentes subprocesos de un proceso se pueden asignar a diferentes núcleos de un multinúcleo procesador, proporcionando así paralelismo dentro de los procesos. Los subprocesos pueden ser proporcionados por el sistema en tiempo de ejecución como subprocesos de nivel de usuario o por el cómo subproceso del kernel. Los subprocesos de nivel de usuario son administrados por un subproceso biblioteca sin soporte específico del sistema operativo. Esto tiene la ventaja de que un cambio de un subproceso a otro se puede hacer sin interacción de la operación sistema y, por lo tanto, es bastante rápido. Una de las desventajas de la gestión de subprocesos en el nivel de usuario proviene del hecho de que el sistema operativo no tiene conocimiento sobre la existencia de subprocesos y gestiona procesos completos únicamente, por lo tanto, el sistema operativo no puede asignar diferentes subprocesos del mismo proceso a diferentes recursos de ejecución y todos los subprocesos de un proceso se ejecutan en el mismo recurso de ejecución. Además, el sistema operativo no puede cambiar a otro subproceso si un subproceso ejecuta un bloqueo de la operación de E/S. En su lugar, el programador de CPU del sistema operativo suspende todo el proceso y asigna el recurso de ejecución a otro proceso. Estas desventajas se pueden evitar mediante el uso de subprocesos del kernel, ya que el funcionamiento el sistema es consciente de la existencia de hilos y puede reaccionar en consecuencia. Esto es especialmente importante para un uso eficiente de los núcleos de un sistema multinúcleo. Más los sistemas operativos admiten subprocesos en el nivel de kernel.
Ejecución de los modelos para hilos
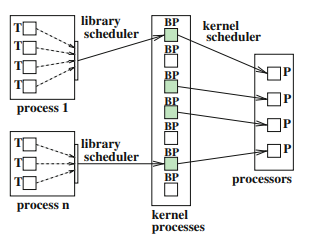
Si el sistema operativo admite la administración de subprocesos, hay dos posibilidades para la asignación de subprocesos de nivel de usuario a subprocesos de kernel. La primera posibilidad es que genere un subproceso de kernel para cada subproceso de nivel de usuario. El programador de la operación hace que el sistema seleccione qué subprocesos del kernel se ejecutan en qué momento. Si es múltiple los recursos de ejecución están disponibles, también determina la asignación de los subprocesos del kernel a los recursos de ejecución. Dado que cada subproceso de nivel de usuario se asigna exactamente a un hilo del kernel, no hay necesidad de un programador de biblioteca. La segunda posibilidad es utilizar una programación de dos niveles donde el programador de la biblioteca de subprocesos asigna los subprocesos de nivel de usuario a un conjunto determinado de subprocesos de kernel. El programador del sistema operativo asigna los subprocesos del kernel a la ejecución disponible de recursos. Dependiendo del hilo biblioteca, el programador puede influir en el programador de la biblioteca, seleccionando un método de programación como este es el caso de la biblioteca Pthreads. El programador del sistema operativo, por otro lado, está sintonizado para un uso eficiente de los recursos de hardware, y normalmente no hay posibilidad de que el programador pueda influir directamente en el comportamiento de este programador. Esta segunda posibilidad de mapeo generalmente proporciona más flexibilidad que un mapeo 1: 1, ya que el programador puede adaptar el número de subprocesos a nivel de usuario al algoritmo específico o aplicación.
Estados de los hilos
· Recién generado: El hilo acaba de generarse, pero aún no se ha realizado cualquier operación.
· Ejecutable: El subproceso está listo para su ejecución, pero actualmente no está asignado a cualquier recurso de ejecución.
· En ejecución: El subproceso está siendo ejecutado actualmente por un recurso de ejecución.
· Esperando: El hilo está esperando que ocurra un evento externo; El subproceso no puede ejecutarse antes de que ocurra el evento externo;
· Terminado: El hilo ha terminado todas sus operaciones.
Visibilidad de datos
Los diferentes subprocesos de un proceso comparten un espacio de direcciones común. Esto significa que las variables globales de un programa y todos los objetos de datos asignados dinámicamente pueden ser acceso por cualquier subproceso de este proceso, sin importar cuál de los subprocesos haya asignado el objeto. Pero para cada subproceso, hay una pila de tiempo de ejecución privada para controlar la función llamadas de este hilo y para almacenar las variables locales de estas funciones. Los datos guardados en la pila de tiempo de ejecución son datos locales del hilo y los otros subprocesos no tienen acceso directo a estos datos. En principio, es posible para darles acceso pasando una dirección, pero esto es peligroso, ya que mientras los datos sigan siendo accesibles, no se pueden predecir. El marco de pila de una llamada a función es liberado tan pronto como finaliza la llamada a la función. La pila en tiempo de ejecución de un subproceso existe sólo mientras el hilo esté activo; Se libera tan pronto como finaliza el subproceso. Por lo tanto, un valor devuelto de un subproceso no debe pasarse a través de su pila de tiempo de ejecución. En su lugar, se debe utilizar una variable global o un objeto de datos asignado dinámicamente.
Referencia